ELECTRA
Electrifying The Training



If you are interested in Deep Learning (especially NLP), then you might have heard of BERT and its friends(bigger and smaller ones!). At the heart of these models is a very "Attention" seeking architecture called "Transformer".
ELECTRA released by Google in March 2020, uses a novel approach for training on corpora. Unlike BERT and co.
To understand this, we must first explore two ideas:
- How language models(using Transformers) learn
- An overview of Generative models(GAN training)
but before diving into these, Let's have a rough idea of Deep Learning in NLP.
Representing Words in numbers
A word must be represented as a vector before feeding it to a deep learning model. This can be done using so many ways (one-hot encoding, Word2Vec, pretrained embeddings). Think of this as a vocabulary of N words, and every word represented using a d dimensional vector.
Language Modelling
We can think deep learning models as Universal Function approximators, So how do they learn the langugage? how they represent? Turns out, we can train them by asking them to predict the next word in a sentence by using the context of previous words.
Let's do a small exercise. Try to predict the next word.
- During this pandemic of COVID-19, Everyone should wear a ... .
- Because of the dress code, Everyone should wear a ... .
For the first, the probability of the word 'mask' is very high. (Although, It should be complete 1. Stay Safe!)
and for the second one, maybe a type of clothing.
So, this is called Language Modelling(LM), in which we try to learn the language(structure, semantics and hopefully everything) mathematically by predicting next word using previous words(context).
Masked Language Modelling
Is predicting next word the only way to learn? Not really, BERT used something called MLM(Masked Language Modelling).
Unlike sequential models(RNN, LSTM, GRU) which takes one word at a timestep, Transformer Encoder of BERT can take entire sequence of input together and process it. so there's no meaning of predicting next word, as the next word would be exposed to internally. This led to masked tokens. Randomly, replacing 15% of tokens with "[MASK]" token and asking model to predict the most probable word for "[MASK]"
- During this pandemic of COVID-19, Everyone should [MASK] a mask.
- Because of the dress code, Everyone should [MASK] traditional clothes at party.
Now, The model has to predict the probability distribution over vocabulary to get the maximum likely words in place of masked words. Thus, the task is called Masked Language modelling.
This approach of BERT achieved SotA in so many tasks.
This can be seen as a denoising autoencoder task. In which, the model is given an input with noise, and it has to output a denoised/cleaned representation of input(here, input:masked sentences. output: predictions for masks. thus, recovered output).
Generative Training
You might have heard of GAN(Generative Adversarial Networks). There is a generator and a discriminator. You can think of this as a game of "chor(thief)-police".
Generator: Generate samples that are so realistic from a distribution of input samples and the goal here is to fool the discriminator. (chor)
Discriminator: Criticize the output generated by the generator about whether it is a real or a fake sample. (police)
The training is interesting! The better either one gets, other also improves!
We refreshed the ideas of MLM and GANs, but how they relate to ELECTRA. Turns out very much. ELECTRA introduced a new learning methodology called "replaced token detection". You get a rough idea of what it could be. The input is again corrupted but instead of masking, the tokens are replaced by other tokens. and the task is to detect whether a token(a word represented by a number) is genuine or corrupted(real or fake). A new self-supervised task for language representation learning.
Now comes the GAN part. MLM trains model as a generator, while replaced token detection trains as a discriminator. The advantage is that the model gets to learn from all tokens, not just the masked out small sub-set. However, one thing to note here is that the training is not adversarial. The model is trained with maximum likelihood rather than adversarial loss due to the difficulty of applying GAN to text.
So, what does ELECTRA stands for? "Efficiently Learning an Encoder that Classifies Token Replacements Accurately"
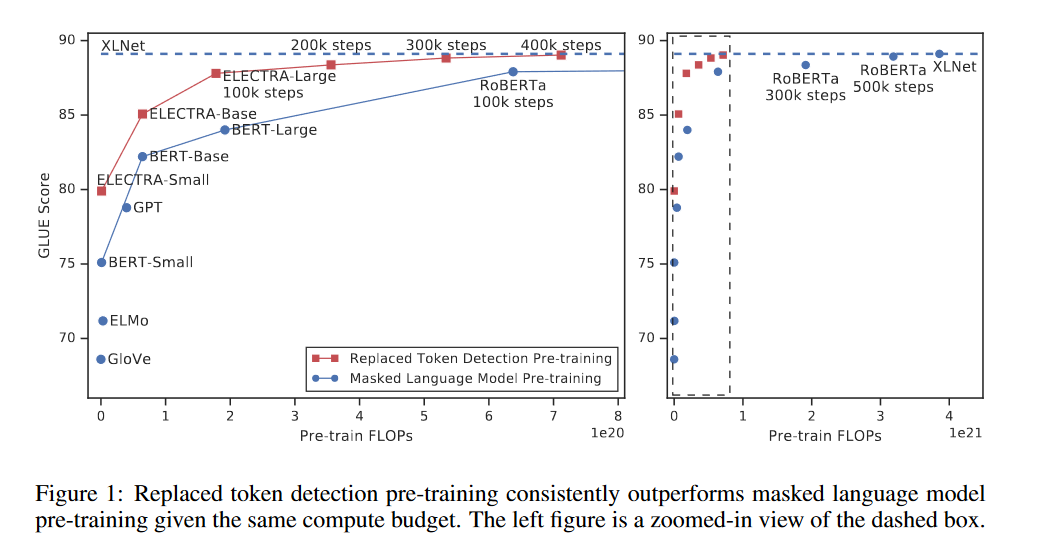
As we can observe from the training progress, The ELECTRA seems to converge faster. The reason is that the model is learning from all the tokens, thus it gets more ideas of tokens and the language compared to MLM tasks. This seems more robust. Look at the image on right, ELECTRA matched similar performances of RoBERTa and XLNet with about 25% of the compute! (FAST)
This is about the discriminator, but what about the generator(how to get the corrupted tokens). Should we do it manually? The GAN approach is at the rescue. We can use a generator model(preferably small) and ask it to predict a distribution(probability) over tokens and then the new tokens can be fed to the discriminator.
From where do the replacements come? You guessed right. A generator to adultrate the inputs. A small model that can give distribution over tokens can be used. Authors have used a BERT-small as a generator on a Masked Language Modelling task. (reminder, it is trained on maximum likelihood, instead of a adverserial loss.) Another observation, The Generator isn't given a noise vector as input like GANs are given.
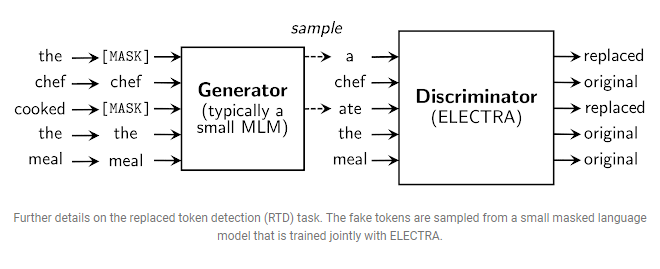
Around 15% of the tokens are masked. The outputs of Generator is fed to Discriminator. Thus we have can diffrentiate between a real(not masked) and a corrupted(masked and predicted by Generator) tokens on which the Discriminator can be trained(on a loss function).
So, is the discriminator always distinguishes on 15% of the tokens that are corrupted? No.
Isn't the goal of MLM is to generate correct words? and won't this lead to only real tokens for descriminator? Yes. If the generator outputs correct word then it is considered "real" when fed to the discriminator. Authors found this formulation to perform better on downstream tasks.
LOSS(ES)
Generator loss:
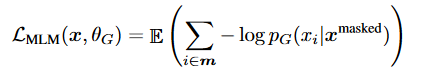
let's take an example,
vocabulary: [During, this, pandemic, everyone, should, wear, a, mask, and, take, care, of, themselves]
inputG: During this pandemic, Everyone should [mask] a mask and take [mask] of themselves.
outputG:
[MASK]1: [0.06253422, 0.10410041, 0.0609353 , 0.0611319 , 0.07645429, 0.0834228 , 0.05501198, 0.09041031, 0.06122133, 0.09231945, 0.05474751, 0.0673528 , 0.1303577 ], a probability distribution over every token in vocabulary. here, the selected token would be "themselves"
for [mask]1: where the answer should be "wear", so probability of "wear" should be high but the output is "themselves".so the sentence that will be fed to Discriminator will be.
corrupted sentence: During this pandemic, Everyone should themselves a mask and take care of themselves.
Discriminator Loss
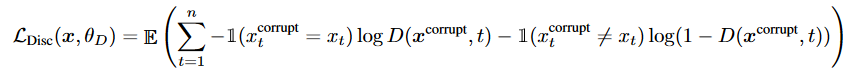
inputD: During this pandemic, Everyone should themselves a mask and take care of themselves.
outputD:[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
Combined loss
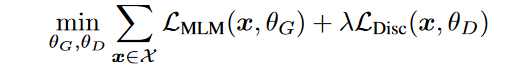
NOTE: Backpropagation updates from this loss isn't done on generator.
This has resulted in a very good performance in so many benchmarks. It achieves State-of-the-art results in SQuAD 2.0.
The released code is very simple to train on GPU and you can explore more using Colab. Three pre-trained models ELECTRA-small, ELECTRA-base, and ELECTRA-Large are also released.
So, if you want to train or fine-tune your own models, checkout https://github.com/google-research/electra
I will be sharing my colab notebook with this. Hope this effort to explain helped you.
Stay tuned. Take care and stay safe.

Acknowledgments: Thanks to Manu Romero for suggeting ELECTRA for my model
Currently, Working on Language models for Indian Languages (Gujarati, Samskrit, and Hindi as of now). I will upload the code soon. Looking forward for suggestions and feedback.